






Anwendungsbereiche



„Im Gegensatz zu anderen Systemen, mit denen ich gearbeitet habe, ist edu-sharing total intuitiv und aufgeräumt.“
Bildungscloud | E-Learning | Open-Source Software | Anbieter
edu-sharing: Open Source für Bildungscloud & E-Learning
Mit edu-sharing Software können Lernplattformen, u.a. Bildungssoftware-Systeme, miteinander vernetzt werden, um Lerninhalte, Metadaten und Tools auszutauschen und in einer Bildungscloud auffindbar und in allen angeschlossenen Systemen nutzbar zu machen. Dieser Grundidee entspringt unser Slogan: :
Alles vernetzen, alles finden, alles nutzen, verbessern und teilen
Die edu-sharing Software ist:
- eine Bildungscloud-Lösung für Vernetzung von E-Learning-Infrastrukturen
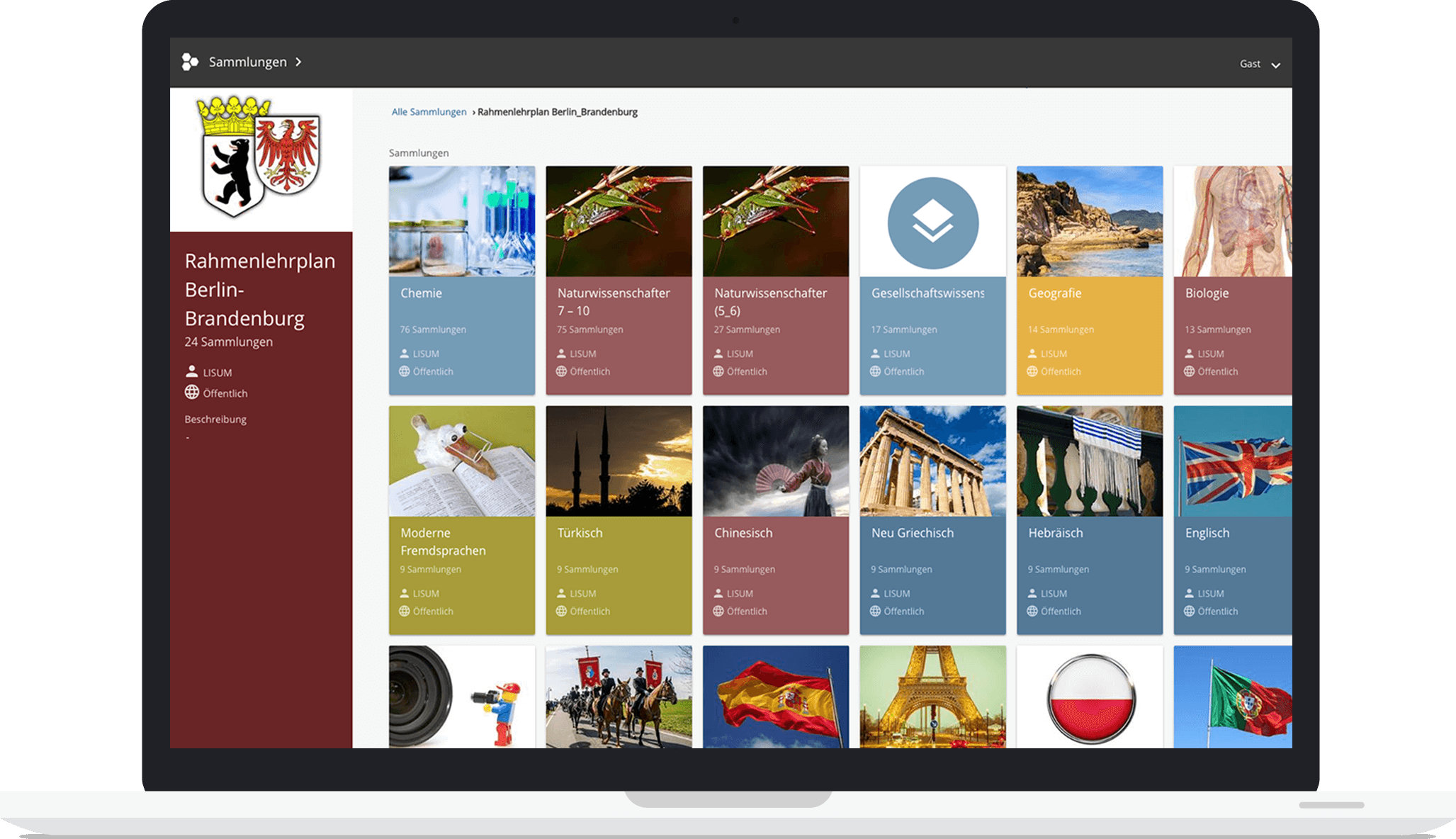
- ein OER-Lösung für eine zentrale Suche mit pädagogischen Sammlungen
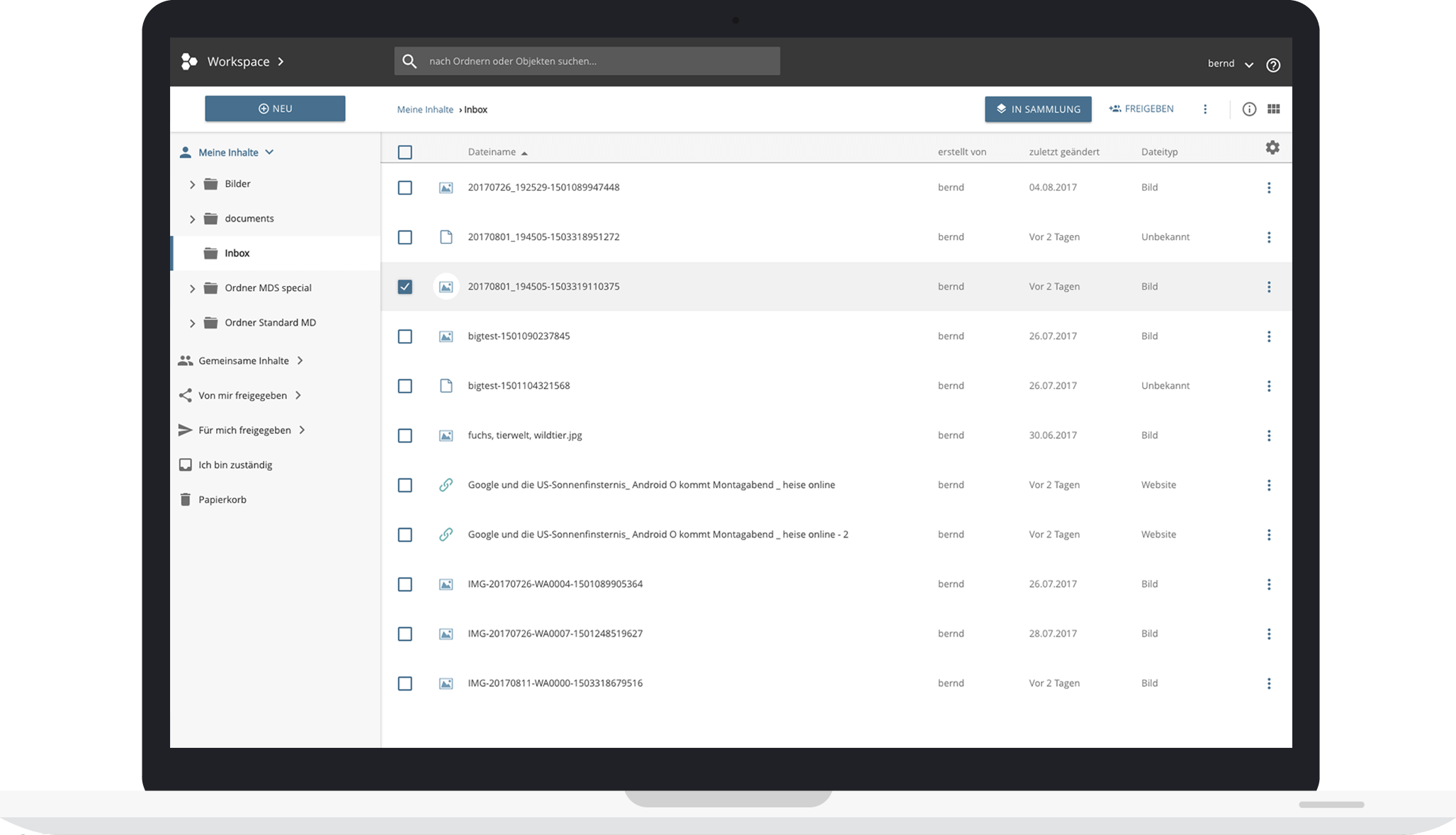
- ein Bildungs-Cloudspeicher zum Verwalten und Teilen von Lernmaterialien, Tools und didaktischen Szenarien
edu-sharing wird beispielsweise in Nordrhein-Westfalen als landesweite Schulcloud-Lösung, in Berlin und Luxemburg als Landeslösung für OER genutzt.Diese Webseite bietet nicht nur das Open Source Produkt und Materialien zum kostenfreien Download, sondern auch Support der Service- und Entwicklungspartnern. Erfahren Sie von zentralen Ansprechpartner in Webinaren, wie Sie die moderne Bildungssoftwarelösung für sich nutzbar machen.
„Sehr funktional, sehr schick und guter Support!“
Mehrwerte

Open Source & anpassbar
Auch unterwegs sammeln und teilen
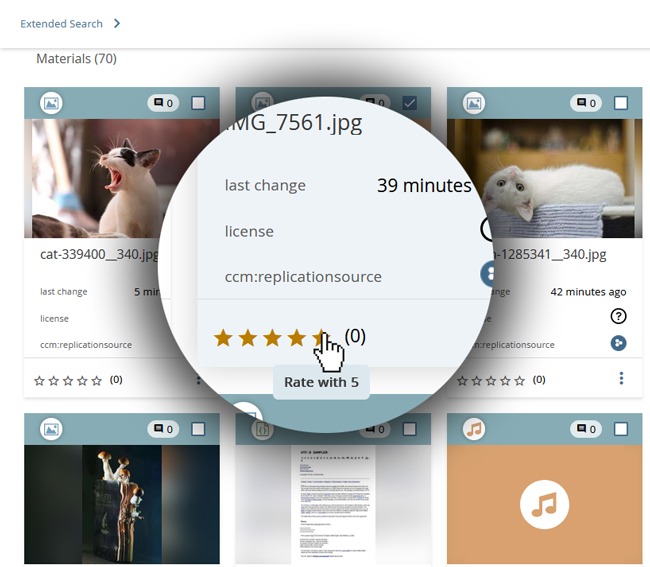
Beim Surfen unterwegs oder zu Hause ein schönes Fundstück entdeckt? Einfach mit der edu-sharing App in private oder gemeinsame Lerninhaltesammlungen einsortieren.
Eine temporäre Sammlung für die nächste Unterrichtsstunde lässt sich ganz leicht aus neuen Internetfundstücken und aus bereits in edu-sharing gesammelten Inhalten zusammenstellen.